
前言
当下,AI 大模型蓬勃发展,各行各业都在尝试与 AI 结合,在其之上做各种工程化的实践与应用。
出于工作需要,我们组要为 AI 训练、推理到落地应用的全过程提供可观测监控的方案,借此机会,我对当前 AI 领域的相关基础概念、背景和生态做了调研和学习,总结成这篇科普文章。
随着后续学习和工作的开展,也许会继续分享我们在 AI 可观测领域的一些技术实践细节,希望我能坚持写完,形成一个系列文章吧:)。
本文不涉及特定神经网络模型的结构设计细节。
AI 模型
什么是 AI 模型?
为了便于后文的介绍,我们首先为 AI 模型给出一个直观的定义。如下图所示,输入集合经过函数 的计算,得到一个输出集合。
函数 就是一个 AI 模型。
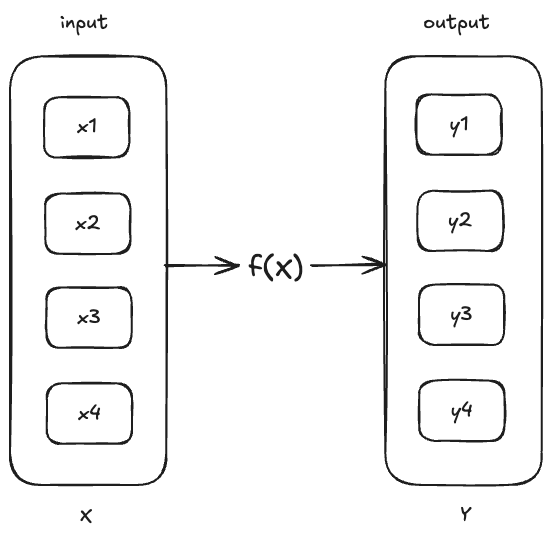
让我们给函数 一个具体的表达式:,这是一个线性函数,拥有两个参数: 和 。
函数 就是一个参数量为 2 的 AI 模型。
至此,我们可以给 AI 模型一个通俗的定义:AI 模型是一种「万能函数拟合器」。
我们常说的大模型(LLM),就是指参数量至少为 10 亿(1B)的 AI 模型。
什么是模型训练?模型训练在做什么?
我们需要 AI 模型的最初目的,是为了使用已知数据来预测未知数据。
让我们回到 这一模型上,如果我们有一系列的已知数据值,如下表所示:
| x | y |
|---|---|
| 1 | 4 |
| 2 | 7 |
| 3 | 8 |
可以得到如下图示:
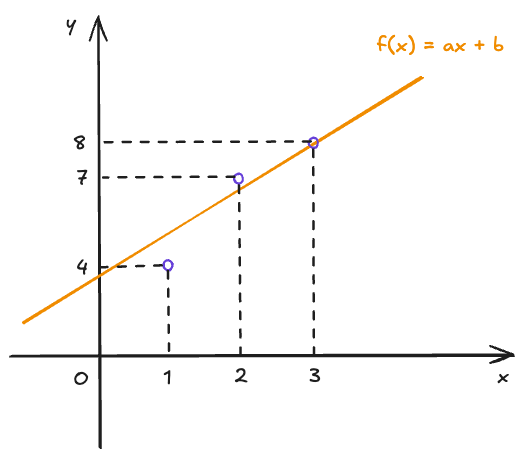
我们期望训练的模型 能够通过学习这些已知数据,确定参数 和 的值。这样一来,当我们输入 时,模型可以给出一个预测值 。
学习已知数据,确定模型参数的过程,就叫做「模型训练」。
模型预测值与实际值之间是有误差的,如上图所示,三个已知数据点并不刚好落在我们的模型 上。我们将模型的预测值 与实际值 之间的误差定义为「损失」,损失越小,表明模型预测越准确。
损失的大小可以使用「损失函数」来计算,损失函数形如 。
有很多数学方法可以定量地表达模型在已知数据集上的损失程度,这些方法可以被表达为一个以模型参数为自变量的函数,我们将这种函数称为「代价函数」。
以模型 为例,它的代价函数可以表达为 。给定一组 、 参数,代价函数 的值就可以表达模型 在一个已知数据集上的预测准确度。
所以,模型训练的目标就是找到一组模型参数,让模型在一个已知数据集上的代价函数值最小。
模型的分类
到目前为止,我们都在用 这一线性函数作为我们的 AI 模型示例,但在实际的应用中,模型是多种多样的:支持向量机、逻辑回归、神经网络…它们的函数表现形式各不相同,但通常都属于非线性函数。
我们将特别介绍神经网络模型,当下热门的 AI 模型几乎都属于神经网络模型。
神经网络模型
神经网络模型仍然是一个函数 ,接收输入集合 ,输出集合 。不同的是,他的函数表达式通常不使用代数形式表达,而使用以「神经元」为基本单位的拓扑图来表示。
下图展示了一个神经元的基本结构:
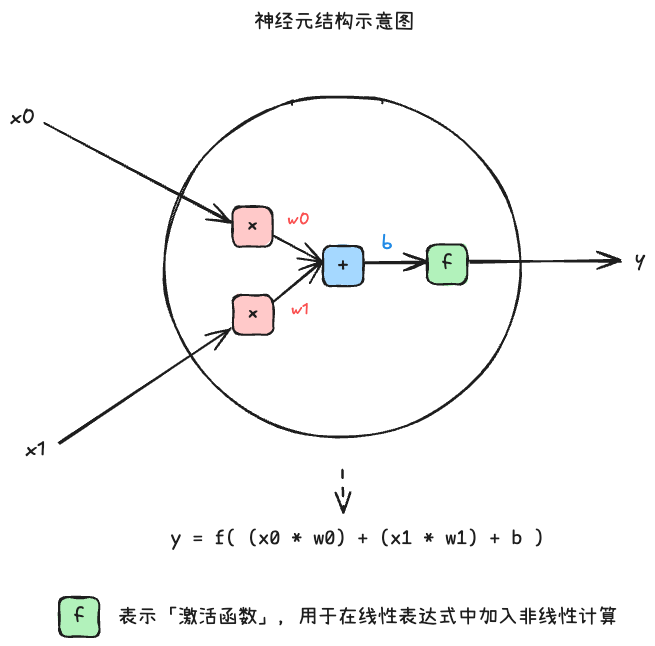
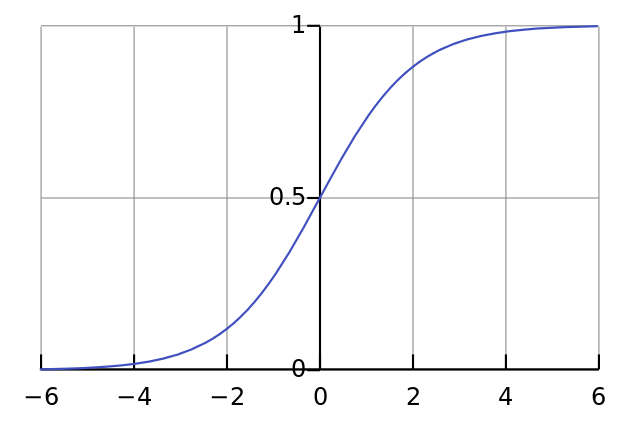
、 表示权重, 表示偏置, 表示激活函数,它是一种简单的非线性函数。一个常见的激活函数是 Sigmoid 函数,它的表达式是 ,如下图所示:
对于输入的数据,神经元内部首先进行了线性表达式计算,再经过激活函数的计算后,输出一个结果值。、、 就是这个神经元的参数。
如果我们将神经元视作一个积木块,构建神经网络结构就是一个搭积木的过程。如下图所示,我们用两个神经元( 和 )组成了一层神经网络:
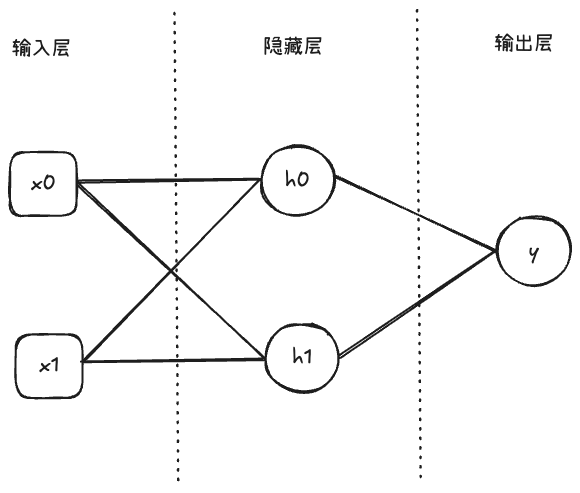
神经网络的第一层称为「输入层」,最后一层称为「输出层」,其余均为「隐藏层」。输入 、 分别经过神经元 、 的计算后,到达输出层 进行输出。
一个神经网络可以由一个或多个隐藏层组成,「深度神经网络」即隐藏层数达数十层的神经网络。
神经网络模型的研究者们在研究什么?
人们发现,不同的网络结构在不同领域的处理任务下能力表现不同。例如,将隐藏层的层数设置为某个数时,相同数据集下的预测表现远好于其他层数,地球上还没有人能解释为什么,但它能工作。
因此,研究者们针对不同领域的任务研究不同的神经网络结构,有的可能具备循环结构(循环神经网络),有的则增加了特殊的处理层(CNN 中的卷积层)等等。
研究者们提出了各种各样的神经网络,并依据神经网络结构的不同,对他们进行分类。大名鼎鼎的 Transformer 就是其中的一种神经网络结构。
神经元的输入向前传递获得输出的过程称为「前馈」,因此,上图这样简单的神经网络也称为前馈神经网络(更准确的说,属于前馈神经网络中的多层感知机)。
神经网络模型在训练什么?
无论是何种网络结构,本质上都是一个数学函数,有着不同数量的参数,与文章开头的 函数无异。
因此,训练神经网络模型与训练一般模型一样,目的是通过调整神经元中的参数,在训练数据集上最小化代价函数。
上文提到, 的代价函数形如 ,在计算机上自动地最小化该函数的策略一般是梯度下降算法:
- 任意选定一个初始参数值
- 代入 正向计算出预测值
- 将 、 代入 ,计算出代价函数值
- 变动参数 和 ,循环步骤 2、3,使 向递减的方向移动
- 循环步骤 4,直到 收敛到一个稳定值
其中,实现步骤 4 要求程序知道调整 或 后 值的变化情况(是会增大?还是会减小?)。因此,需要分别求得 对 和 的偏导数,由偏导数的正负来确定方向。
神经网络的参数一般是从输出层开始,由后往前按照链式法则求导,这样可以复用已计算的结果。与前馈传播相对应,这一过程被称为「反向传播」。
训练模型就是一个不断进行正向和反向计算来优化参数的过程。
AI 模型训练框架
如果我们总结上面的介绍,会发现无论何种 AI 模型,都经过了设计模型、训练模型(优化参数)的过程。这一过程涵盖了大量重复的数学计算,于是催生出了需求:模型设计抽象、优化数学运算性能、自动反向传播求导能力,这就是 AI 训练框架解决的问题。
AI 模型训练框架为设计神经网络结构提供了「积木」的抽象,将各种数学运算封装为高度优化的算子,并提供了常见反向传播算法的优化器实现(例如上文提到的梯度下降算法)。
神经网络的研究者利用算子定义好网络结构,提供数据集,并指定优化器实现后,AI 训练框架上便会自动实现反向传播,自动地优化网络中的参数。
除此之外,AI 模型训练框架还能针对不同的硬件或平台进行算子实现的优化,并提供分布式训练的能力。所有的目标都是为模型研究者屏蔽实现和训练的细节,使他们关注模型结构的设计。
常见的 AI 模型训练框架有 PyTorch、TensorFlow,百度飞桨也属于 AI 模型训练框架。
训练出来的模型是一个什么文件?
训练好的模型是一个包含网络结构和参数值的二进制文件(有时也只包含网络结构而没有参数值)。不同的 AI 模型训练框架可能输出不同的文件格式,也存在一些各家均支持的开放格式。
AI 模型的开源,通常就是指这一文件的开源。研究者可以透过模型文件得到网络结构的细节(有时开源的是已训练模型,包含参数值),对照着公开论文学习其网络结构的设计思路。
AI 模型推理框架
什么是模型推理?如何进行模型推理?
「使用训练好的模型」这一过程,就叫做「模型推理」。
用户给定输入数据,模型接收输入,经过计算后输出预测值,这一过程就叫做模型推理。
实现模型推理(或者说运行模型)依赖模型推理框架。我们可以把训练好的模型文件类比为 jar 文件,模型推理框架类比为 JVM,模型推理就类比为使用 JVM 读取 jar 文件运行一个 Java 程序。
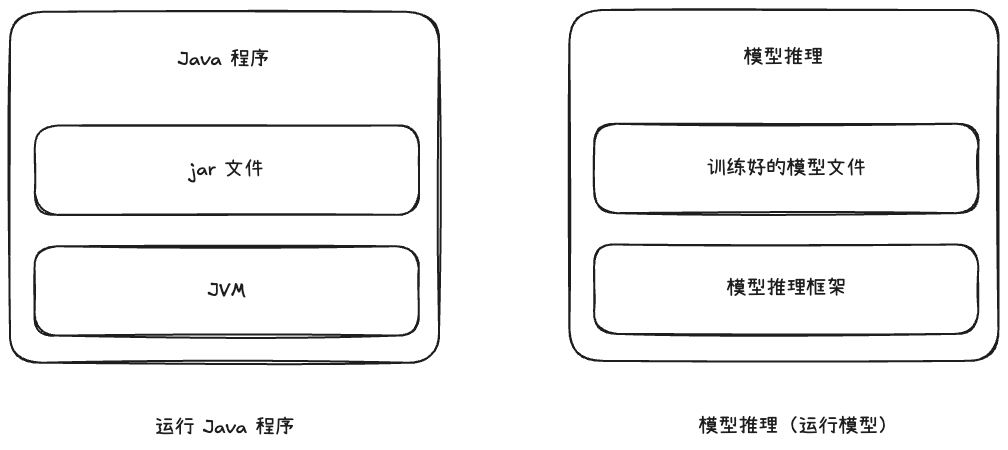
模型推理框架的开发者们在做什么?
正如不同的硬件或平台有着不同的 JVM 实现一样,不同的模型推理框架也针对不同的硬件或平台做了优化。
除此之外,由于某些特定结构的神经网络模型大规模应用(例如 Transformer 模型),模型推理框架可以针对这些神经网络模型做结构上的特定优化,从而在几乎不损失计算结果精度的情况下,大幅提高模型推理的速度。
总结来说,模型推理框架提供了以下能力:
- 针对常用的、特定的模型,提供特定于硬件/平台的自动推理优化方案
- 针对不同的硬件/平台,提供模型的精简(例如,在一个小型化设备上跑大模型,可以将参数的精度下调)
- 有效利用 GPU 集群的资源,尽可能减少显存占用,分布式 & 并行地完成推理(PD 分离等技术)
- 有些模型推理框架还针对 Transformer 类型的模型包装了 OpenAI 兼容的接口,为上层应用提供服务
我们会发现,模型推理实际上就是 AI 模型落地应用的具体表现。在模型能力不变的情况下,提高模型推理性能,就能减少提供 AI 服务的成本。
因此,模型推理优化是各大企业高度重视的热门领域。就像各大企业曾经热衷于为 JVM 增加各种定制优化来提高 Java 程序的运行效率一样,当下层出不穷的模型推理框架和推理优化技术也是这一想法在 AI 模型领域的反映。
将传统应用领域的优化经验应用到 AI 模型的工程领域,就形成了多种多样优化方案:并行、分布式、硬件优化…
AI 应用
上述概念适用于所有模型,不针对于 Transformer 模型。由于基于 Transformer 的 LLM 近年及其热门,下面提到的 AI 模型大多表示基于 Transformer 的大模型。
可以看到,AI 模型无论是在学术还是在工程领域,都处于一个蓬勃发展的阶段。从模型的设计、训练到推理落地的过程,都有着大量的技术空白等待填补。
然而,这些空白多数有着一定的门槛,要么要求具备一定的数学基础,能够对网络结构或算法进行优化,要么要求具备一定的工程基础,能够在底层计算与网络设备上进行优化。
从上层应用的开发者和产品设计角度看来,AI 模型就是一个可以使用的黑盒,基于这样一个黑盒,业界创造了多个关于 AI 的概念。
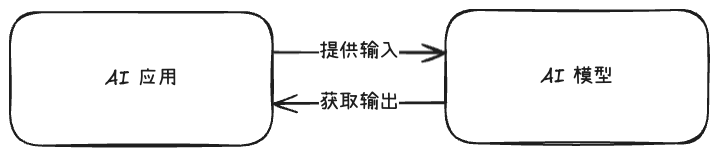
什么是 AI 应用?
AI 应用就是调用 AI 模型能力的普通应用程序。
什么是 AI 智能体 / AI Agent?
既调用 AI 模型能力,又调用普通程序的普通应用程序。
什么是 MCP 协议?
一种 RPC 调用协议,AI 应用可以使用此协议远程调用 AI 模型的能力。