
前言
现代互联网服务是由数量庞大的微服务组成的,这些微服务通常部署在异构的分布式集群中,通过网络连接在一起。这种服务架构使得一个庞大的软件系统可以得到良好的维护,各个团队负责其软件模块的开发与维护,而无需关心系统整体的工作细节。
但如果从系统整体来看,排查问题则变得非常复杂。用户请求进入系统后,流经多个业务团队的软件模块,并最终在系统中的某个环节出现问题。为了排查这样的一个问题,需要理解系统中各个软件模块的工作细节,这就要求各个团队的研发人员参与其中,依次断言问题来自下游,直到定位问题产生的根源。
为了让对系统实现细节不甚了解的运维人员也能快速定位问题根源,需要一种技术手段来跟踪请求在系统中的数据流向,这就是分布式链路追踪技术。
在可观测性的概念中,分布式链路追踪技术特指用于采集、处理和展示 Trace(链路)信号的能力,并能与 Metric(指标)、Log(日志) 信号产生一定的关联。本文从建设系统整体的可观测能力角度出发,对业界现有的开源分布式链路追踪技术进行调研分析。
调研
Dapper
Dapper[1] 是 Google 早年生产环境下的分布式跟踪系统,分布式链路追踪技术的许多概念均基于 Dapper 论文发展而来。
数据结构
考虑这样一种普遍的场景,当用户的请求进入系统后,将会依次触发系统内各软件模块的 RPC 调用。我们知道,请求最终会在系统内部终止处理,因此,如果将每个函数看作一个节点,每个 RPC 调用看作一条有向边,则整个调用链构成一个有向无环图,即树型结构。
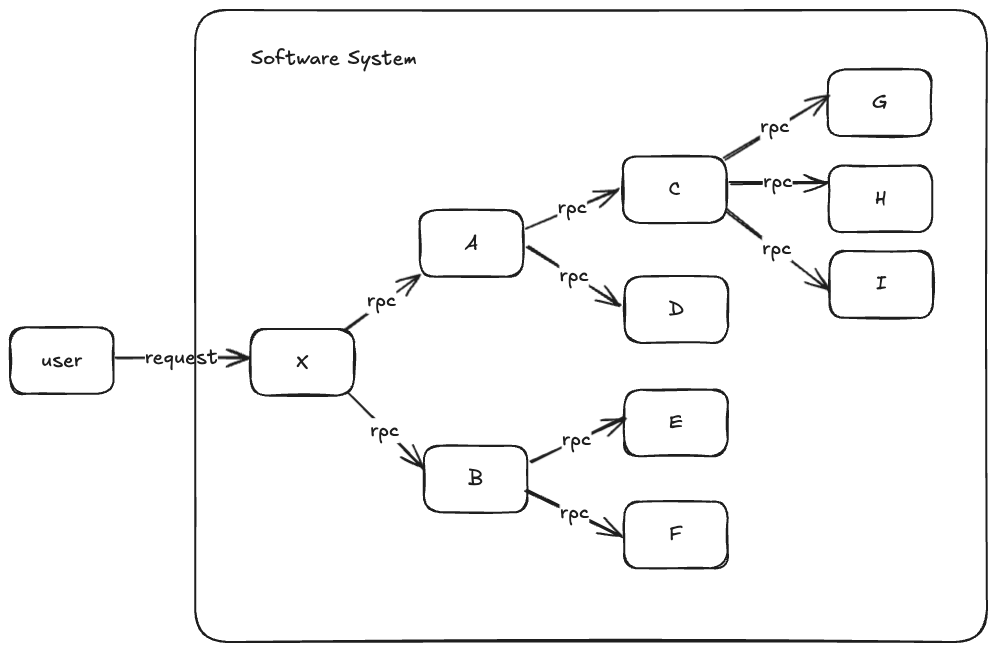
基于这样的分析,Dapper 提出了跟踪树(Trace Tree)结构。每个请求都会产生一个新的跟踪树,每个跟踪树被赋予全局唯一的 Trace ID 用以区分。跟踪树的节点被称之为 span,除了根 span 外,每一个 span 都拥有一个唯一的父 span。
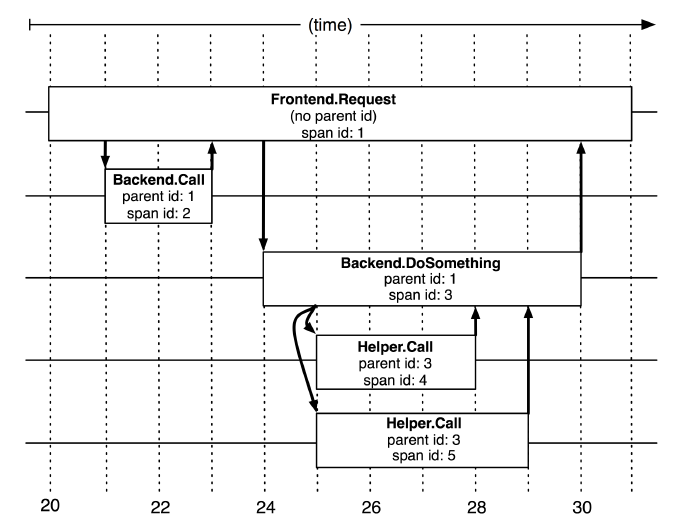
事实上,span 是对调用链上的一个具体函数的抽象,通过 span 提供的信息,我们应当可以分析得到该函数的运行性能概况。最为常见的指标是函数的运行时间,因此,一个 span 通常包括了 RPC 调用的起始和结束时间。
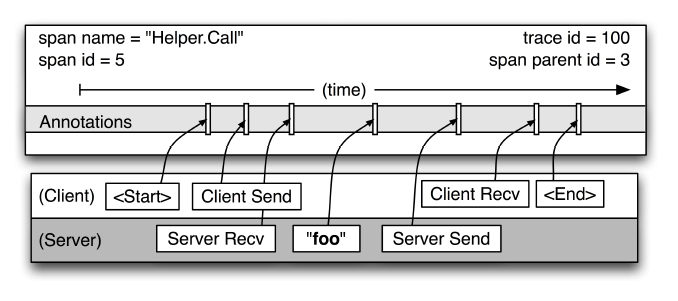
但 span 可以包含更多能够用于函数性能分析的相关信息。在 Dapper 中,span 提供的信息被称之为 Annotation,Dapper 允许业务方添加文本 Annotation 与 Key-Value 映射类型的 Annotation,可用于存放二进制数据。
数据采集
Dapper 结合两种方法对应用程序进行插桩:
- 引入专用 SDK。Dapper 提供了一组 API,允许开发人员向
span中添加自定义的 Annotation 信息。 - 在统一的 RPC 框架中埋点。Google 内部使用统一的 RPC 框架,Dapper 在 RPC 框架中执行了埋点逻辑,以业务无感的方式记录了 RPC 调用的起止时间。
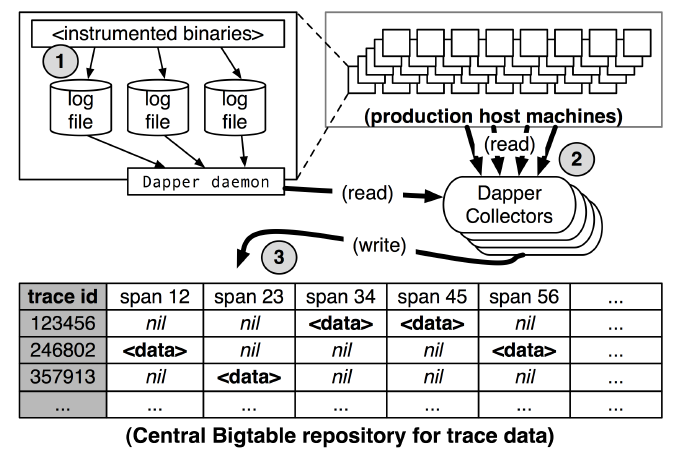
两种方法均会将原始的 span 信息写入本地日志文件中,由 Dapper Daemon 将信息从日志文件中提取出来,经 Dapper Collectors 写入 Bigtable 存储。
SkyWalking
SkyWalking[2] 是一个完整的 APM 解决方案,不仅提供了分布式链路追踪的能力,还包括了 Metric 与 Log 的采集、存储的能力。我们仅关注其分布式链路追踪相关的实现细节。
与 Dapper 相比,SkyWalking 没有提出新的分布式链路追踪概念,沿用了 span 这一概念作为调用链上函数的抽象,其数据结构也构成了一棵跟踪树,以 span 为树节点。
数据采集
在 SkyWalking 中,Agent 负责从应用程序中采集原始 span 信息,并将这些信息以某种协议格式化后,发送至后端。SkyWalking 提供了以下几类 Agent[3]:
- 基于语言的本地 Agent。例如,Java 应用程序可以使用
-javaagent参数指定所使用的运行时代理。对于 Golang 应用,SkyWalking Agent 能够在编译期完成插桩。 - 运行在服务网格上的 Agent。
- 第三方 SDK。通过各种第三方 SDK 提供的 API,允许开发人员向
span中添加自定义信息。SkyWalking 的后端能够正确处理各种协议之间的格式转换。 - eBPF Agent。基于 eBPF 技术无侵扰地收集更多的性能指标。
所有类型的 Agent 均以主动推送的方式将 span 信息写入后端,由后端执行分析与存储,提供查询接口。
SkyWalking 有着非常丰富的基于语言的本地 Agent 生态,极大地降低了现有应用程序接入监控系统的门槛。
Zipkin & Jaeger
Zipkin[4] 是 Twitter 开源的基于 Dapper 的分布式链路追踪系统。因此,其实现思路、数据结构及数据采集都与 Dapper 大同小异。
在 Zipkin 中,采集原始 span 信息的组件被称为 Reporter,而 Reporter 的本质是一个专用 SDK,提供了一组 API 以使用户添加自定义 span 信息。
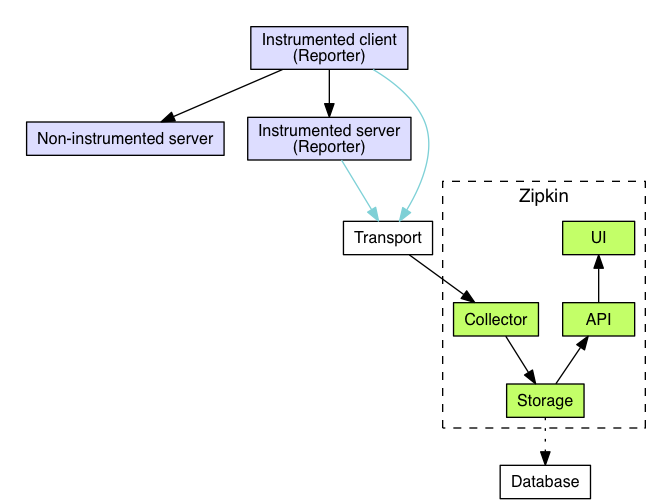
与 Dapper 不同的是,Zipkin 将 span 信息直接发送至后端,而非写入日志中等待拉取。Jaeger[5] 与 Zipkin 类似,使用 SDK 主动向后端推送 span 信息,两者在架构上并无太大的差别。
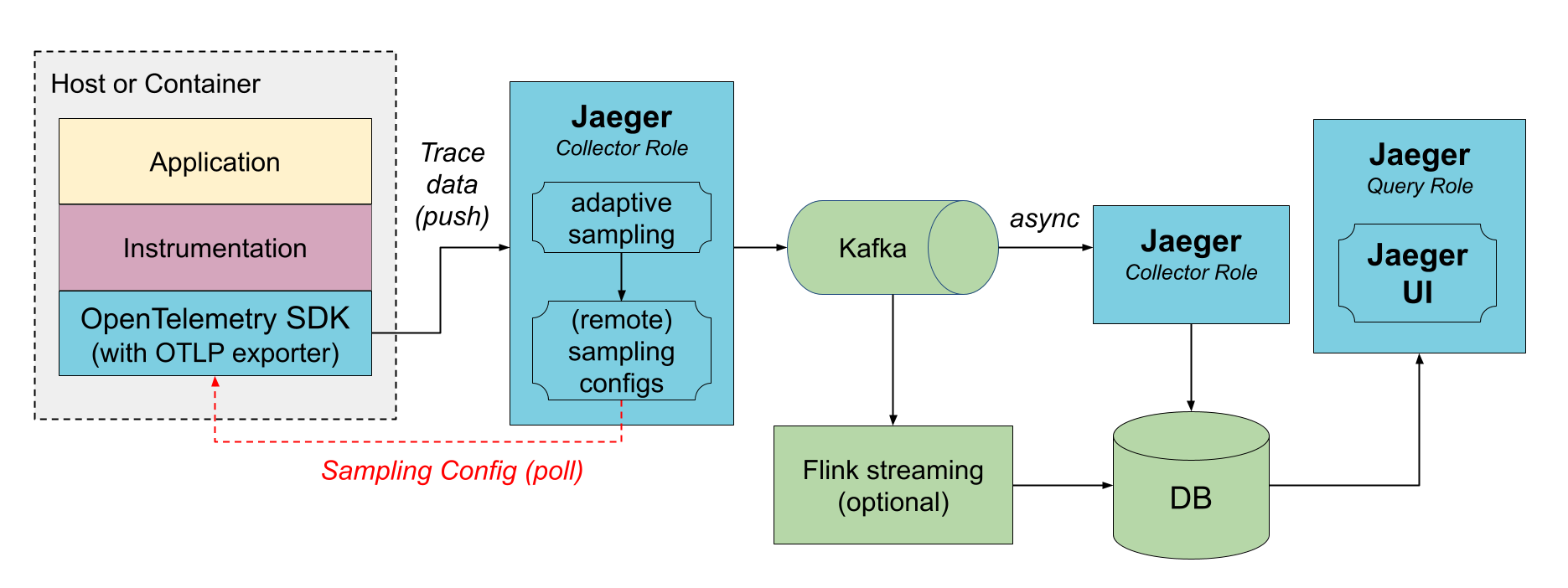
远程配置采样率
分布式链路追踪需要对应用程序的性能影响足够的小,而在某些场景下,某些应用程序有着极高的 QPS,如果对每一个请求都进行采样跟踪的话,难免会对性能产生负面影响。因此,采集端的链路信息采样率配置至关重要。
Jaeger 实现了一种被称为 Remote Sampling 的协议[6],实现该协议的 SDK 能够从一个统一的配置中心里获取采样策略,采样策略定义了每个应用的采样率,采样率各不相同,既可以从文件中定期加载,也能根据流量动态计算。
OpenTelemetry
OpenTelemetry[7] 不是一个分布式链路追踪系统,它是一系列可观测框架和工具包的集合,定义了统一的可观测协议。
对于不同的分布式链路追踪系统,其内部 span 信息的数据结构定义与传输方式均不相同。不同的解决方案提供了不同的 SDK,使得代码和可观测数据与监控系统的选型严格绑定。OpenTelemetry 的出现打破了这种数据孤岛的局面,各 APM 提供商的产品均以 OpenTelemetry 协议(OTLP[8])作为数据传输协议,span 信息的数据结构也得以统一。
除此之外,OpenTelemetry 还提供了一系列语言相关的 SDK 或零代码 Agent 用于采集链路信息,尽管部分工具当前仍处于早期开发阶段,但由于其原生利用了 OTLP 协议的能力,在考虑采集端的选型时,应当优先考虑 OpenTelemetry 生态的相关 SDK 与 Agent 工具。
上下文传播
我们可以将分布式链路追踪视为一个携带上下文信息的数据在系统内流传的过程,由于上下文信息在系统内跨进程传递,必然需要某种介质将其联系起来。
在 OpenTelemetry 中,上下文是一个包含了 trace id 和 span id 信息的对象[9],实际指明了当前所在节点的跟踪树及跟踪树的父节点。传播则是解析和处理上游传递而来的上下文信息,依靠的是某种统一的约定。例如,对于使用 HTTP 协议执行 RPC 调用的请求而言,可以约定在请求头中添加 trace-id 键值传递跟踪树 ID 信息。
各分布式链路追踪系统的私有协议所使用的上下文传播约定各不相同,下表[10]展示了其中一些协议的约定。
| 传输协议 | |
|---|---|
| OpenTelemetry | 使用 traceparent Header 传递 Trace,同时进入 W3C 标准 |
| SkyWalking | 使用 sw8 Header 传递 Trace |
| Jaeger | 使用 Uber-Trace-Id Header 传递 Trace |
| Zipkin | 使用 x-b3-xxx Header 传递 Trace |
上下文信息是通过带内传播的,链路信息通常则是通过带外传播的[4]。尽管 OTLP 协议能够使得不同的采集端所采集的链路信息结构得到统一(例如,使用 opentelemetry-collector[11] 将 SkyWalking 的私有协议转化为 OTLP 协议输出),但它并没有解决跨协议的上下文传播问题,OpenTelemetry 推动 Trace Context 规范进入 W3C 标准[12]正是为了解决此问题。
因此,对于一个软件系统而言,为了能够正确传递和连接上下文信息,内部应当使用统一的传递约定,这意味着应当尽可能采用同一种采集端来完成链路信息的收集。
DeepFlow
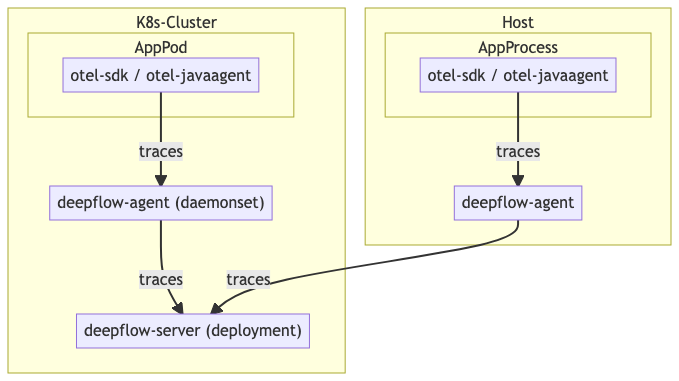
DeepFlow[13] 是采用 eBPF 技术[14]实现零侵扰采集链路信息的一款开源产品。通过 eBPF 技术,相对于插桩式的埋点,DeepFlow 能够采集到来自应用外部的信号,例如系统调用、网络传输等路径的信息。
由于 DeepFlow 的 Agent 与 Server 端通过私有协议紧密相连,实质上形成了一个相对封闭的生态,即在一个系统内,一条调用链的信息必须同时经过 DeepFlow Agent 与 DeepFlow Server 的处理,而无法单独替换任何一方。
为了接入 OpenTelemetry 生态,DeepFlow Agent 接受 OTLP 协议的链路信息作为输入[15],从而合并通过 eBPF 采集的内核级别的链路信息与应用上报的链路信息。除此之外,DeepFlow Server 能够以 OTLP 协议输出其采集的数据。
AutoTagging
DeepFlow Agent 与 Server 之间使用一种私有协议保持长连接通信,Server 会同步 Agent 收集的标签信息。除此之外,Server 与 K8S、CMDB 等第三方业务信息接口保持联系,从而得到业务与应用关联的整体视图。
当采集的指标、链路等数据进入 Server 端时,仅凭 Agent 附加的少量标识,即可将业务全景信息加入标签。
分析
在 2025 年的当下建设一个新的可观测系统,是拥有一些后发优势的,最大的一点优势就是 OpenTelemetry 统一了可观测协议,并得到了各家产品提供商的原生支持。尽管 OpenTelemetry 的相关框架及工具仍处于早期建设过程中,但在架构设计层面上几乎可以断言仅使用 OTLP 协议而非设计私有协议。
从调研结果来分析,一个分布式链路追踪系统主要由三部分组成:采集端、服务端、存储端。
采集端
采集端负责收集链路信息,构造 trace 与 span 信号,将其上报至服务端。根据采集端的作用原理,主要可以分为以下两类:
- 侵入式。通过引入 SDK 手动构造并上报链路信息的方式,如 OpenTelemetry 的一众语言相关 SDK[16]。除此之外,更改 Java 字节码[17]或编译期插桩[18]的自动埋点方式也应当属于侵入式采集,但这类侵入式采集通常无需代码改造。侵入式采集能够得到应用级别的详细链路信息,但可能会对应用性能产生负面的影响。
- 非侵入式。以 eBPF 技术为代表的 DeepFlow Agent 即属于此类采集,对应用的进程空间没有任何侵入,通过内核态中的 Hook 函数实现各链路信息的关联采集。
为 Go 代码进行 OpenTelemetry 零代码插桩是社区近期比较关注的方向。当前存在两种路径,一种是以 opentelemetry-go-instrumentation[19] 为代表的基于 eBPF 技术的运行时拦截插桩,另一种则是以 instrgen[20] 为代表的编译期插桩技术。
但在经过社区讨论[21]后,由阿里云 ARMS 团队与程序语言与编译器团队合作研发[22]并捐赠给社区的 opentelemetry-go-auto-instrumentation[18] 将在未来替代 instrgen 成为 OpenTelemetry 社区官方的 Go 编译期插桩工具[23]。
新的代码仓库位于 open-telemetry/opentelemetry-go-compile-instrumentation。
在当前看来,选择 OpenTelemetry 的零代码 SDK 是一个比较理想的选择。一是由于 OTLP 已成为可观测事实上的行业标准,零代码 SDK 足以使用最小的代码改造量得到最大化的 span 信息粒度;二是非侵入式的采集端通常对系统内核有所要求,并且在采集应用层面上的链路信息时较为困难。
由于协议上的统一,另外一种更佳的选择则是混合使用两种采集端,利用侵入式 SDK 采集应用层面的链路信息,或允许用户自定义细粒度更高 span 信息,再将其与非侵入式采集的内核级别链路信息结合,得到一个完整的调用链全景图,这也是 DeepFlow 与 OpenTelemetry 生态对接的思路[15]。
服务端
服务端可以分为两部分,一部分是提供查询 API 服务,允许用户通过 API 访问存储中的链路信息,得到调用链关系与应用拓扑图;另一部分则是对采集端上报的数据进行加工处理,写入存储端。
这一部分与业务需求的关联较高,开源方案难以覆盖多种多样的业务需求。需要提供哪些查询 API,需要关联哪些业务信息,这些都是服务端需要处理的工作。因此,这一部分选择自研会是比较合适的选择。
存储端
Trace 信号的存储具有以下几个特点:
- 写多读少。在一个高并发的系统中,将不断地产生链路追踪信息,以带外传递的方式写入存储。以采样率 100% 计算,一个请求对应一个 Trace 信号,但每个 Trace 信号拥有数十上百个 Span 信息,每个 Span 信息都应独立存储。而仅在出现问题的时候,用户才会从存储端中读取调用链信息,一般对应于几条 Trace 信号。
- 结构固定。可以将
span信息看成一条高度结构化的日志。
Dapper 在论文中指出他们使用了 BigTable 来进行链路信息的存储[1],这是一种宽列存储。以 trace id 和 span id 作为行和列的稀疏矩阵确实非常利于使用宽列存储,Zipkin 默认也使用了同样宽列存储的数据库 Cassandra。
Jaeger 默认使用 Elasticsearch 进行存储,个人看起来更像是历史原因,因为基于第二个特点,高度结构化的信息完全可以通过合适的索引手段进行检索,而非直接通过文本的全文检索。此外,Elasticsearch 的写入性能也存在较大的瓶颈[25]。
以 DeepFlow、Signoz[24] 为代表的新产品则选择了 ClickHouse 作为存储后端。ClickHouse 能够满足写入性能的要求,存储成本低[25],并且在结构固定的 span 信息检索场景下也能得到很高的查询性能。存储端应当被设计为允许使用不同的存储后端,但 ClickHouse 适合作为一个默认的存储后端选择。
参考文档
- Dapper, A Large-Scale Distributed Systems Tracing Infrastructure(译文)
- SkyWalking - Overview
- SkyWalking - Probe Introduction
- Zipkin - Architecture
- Jaeger - Architecture
- Jaeger - Remote Sampling
- OpenTelemetry - 什么是 OpenTelemetry?
- OpenTelemetry - OTLP Specification 1.5.0
- OpenTelemetry - 上下文传播
- 使用 OpenTelemetry 零代码修改接收 SkyWalking 追踪数据
- OpenTelemetry - Collector
- W3C Recommendation - Trace Context
- DeepFlow - DeepFlow 架构
- DeepFlow - eBPF 是实现可观测性的关键技术
- DeepFlow - 导入 OpenTelemetry 数据
- OpenTelemetry - Language APIs & SDKs
- GitHub - open-telemetry/opentelemetry-java-instrumentation
- GitHub - alibaba/opentelemetry-go-auto-instrumentation
- GitHub - open-telemetry/opentelemetry-go-instrumentation
- GitHub - open-telemetry/opentelemetry-go-contrib
- GitHub - open-telemetry/community - issue #1961
- 面向 OpenTelemetry 的 Golang 应用无侵入插桩技术
- GitHub - Bootstrap Go compile time instrumentation
- Signoz - Writing traces based ClickHouse queries for building dashboard panels
- B 站基于 ClickHouse 的下一代日志体系建设实践
- 得物云原生全链路追踪 Trace 2.0 架构实践
- 分布式链路追踪在字节跳动的实践
- 美团技术团队 - 可视化全链路日志追踪